

Considered one of the extra thrilling functions of decentralized computing which have aroused a substantial quantity of curiosity in the previous 12 months is the idea of an incentivized decentralized on-line file storage system. Presently, if you need your information or information securely backed up “in the cloud”, you could have three selections – (1) add them to your personal servers, (2) use a centralized service like Google Drive or Dropbox or (3) use an present decentralized file system like Freenet. These approaches all have their very own faults; the first has a excessive setup and upkeep value, the second depends on a single trusted get together and usually includes heavy worth markups, and the third is gradual and very restricted in the quantity of area that it permits every person as a result of it depends on customers to volunteer storage. Incentivized file storage protocols have the potential to offer a fourth approach, offering a a lot increased amount of storage and high quality of service by incentivizing actors to take part with out introducing centralization.
A variety of platforms, together with StorJ, Maidsafe, to some extent Permacoin, and Filecoin, are trying to deal with this drawback, and the drawback appears easy in the sense that each one the instruments are both already there or en path to being constructed, and all we’d like is the implementation. Nonetheless, there’s one a part of the drawback that’s notably essential: how can we correctly introduce redundancy? Redundancy is essential to safety; particularly in a decentralized community that shall be extremely populated by novice and informal customers, we completely can not depend on any single node to remain on-line. We might merely replicate the information, having just a few nodes every retailer a separate copy, however the query is: can we do higher? Because it seems, we completely can.
Merkle Bushes and Problem-Response Protocols
Earlier than we get into the nitty gritty of redundancy, we are going to first cowl the simpler half: how can we create at the least a fundamental system that can incentivize at the least one get together to carry onto a file? With out incentivization, the drawback is simple; you merely add the file, wait for different customers to obtain it, and then while you want it once more you may make a request querying for the file by hash. If we need to introduce incentivization, the drawback turns into considerably more durable – however, in the grand scheme of issues, nonetheless not too onerous.
In the context of file storage, there are two sorts of actions that you may incentivize. The primary is the precise act of sending the file over to you while you request it. That is simple to do; the greatest technique is an easy tit-for-tat recreation the place the sender sends over 32 kilobytes, you ship over 0.0001 cash, the sender sends over one other 32 kilobytes, and so forth. Observe that for very giant information with out redundancy this technique is susceptible to extortion assaults – very often, 99.99% of a file is ineffective to you with out the final 0.01%, so the storer has the alternative to extort you by asking for a really excessive payout for the final block. The cleverest repair to this drawback is definitely to make the file itself redundant, utilizing a particular type of encoding to broaden the file by, say, 11.11% in order that any 90% of this prolonged file can be utilized to get well the unique, and then hiding the actual redundancy share from the storer; nonetheless, because it seems we are going to focus on an algorithm similar to this for a unique objective later, so for now, merely settle for that this drawback has been solved.
The second act that we are able to incentivize is the act of holding onto the file and storing it for the long run. This drawback is considerably more durable – how will you show that you’re storing a file with out truly transferring the entire factor? Thankfully, there’s a resolution that isn’t too troublesome to implement, utilizing what has now hopefully established a well-recognized popularity as the cryptoeconomist’s greatest buddy: Merkle timber.
Properly, Patricia Merkle could be higher in some instances, to be exact. Athough right here the plain previous unique Merkle will do.
n = 2^okayfor some
okay(the padding step is avoidable, but it surely makes the algorithm easier to code and clarify). Then, we construct the tree. Rename the
nchunks that we obtained
chunk[n]to
chunk[2n-1], and then rebuild chunks
1to
n-1with the following rule:
chunk[i] = sha3([chunk[2*i], chunk[2*i+1]]). This allows you to calculate chunks
n/2to
n-1, then
n/4to
n/2 - 1, and so forth going up the tree till there’s one “root”,
chunk[1].
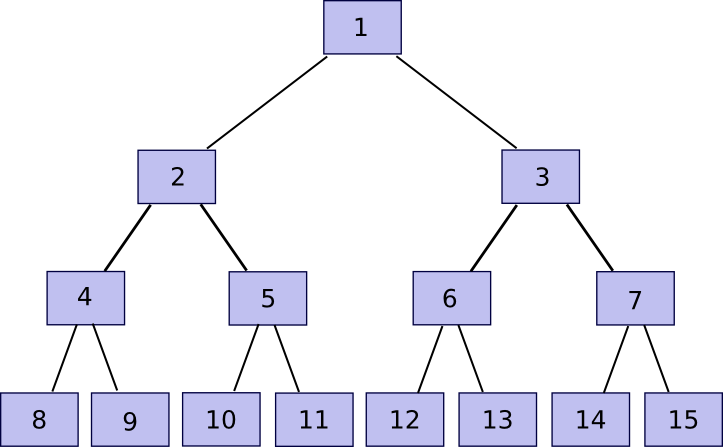
Now, be aware that for those who retailer solely the root, and neglect about chunk[2] … chunk[2n-1], the entity storing these different chunks can show to you that they’ve any explicit chunk with just a few hundred bytes of knowledge. The algorithm is comparatively easy. First, we outline a operate companion(n) which supplies n-1 if n is odd, in any other case n+1 – briefly, given a bit discover the chunk that it’s hashed along with with a purpose to produce the father or mother chunk. Then, if you wish to show possession of chunk[k] with n <= okay <= 2n-1 (ie. any a part of the unique file), submit chunk[partner(k)], chunk[partner(k/2)] (division right here is assumed to spherical down, so eg. 11 / 2 = 5), chunk[partner(k/4)] and so on right down to chunk[1], alongside the precise chunk[k]. Primarily, we’re offering the whole “branch” of the tree going up from that node all the approach to the root. The verifier will then take chunk[k] and chunk[partner(k)] and use that to rebuild chunk[k/2], use that and chunk[partner(k/2)] to rebuild chunk[k/4] and so forth till the verifier will get to chunk[1], the root of the tree. If the root matches, then the proof is okay; in any other case it isn’t.
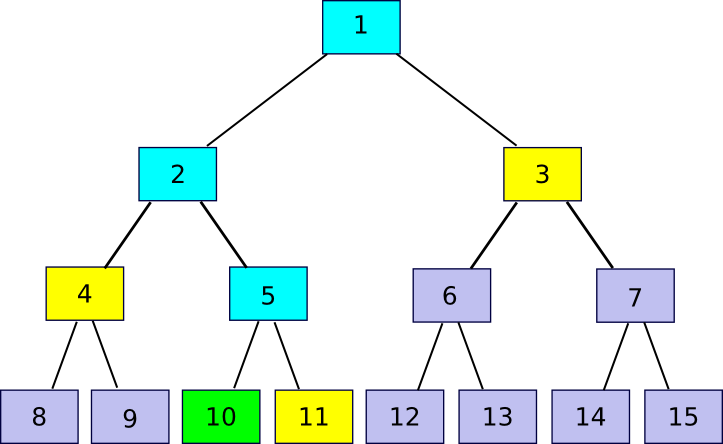
11 = companion(10)), 4 (
4 = companion(10/2)) and 3 (
3 = companion(10/4)). The verification course of includes beginning off with chunk 10, utilizing every companion chunk in flip to recompute first chunk 5, then chunk 2, then chunk 1, and seeing if chunk 1 matches the worth that the verifier had already saved as the root of the file.
Observe that the proof implicitly contains the index – typically you have to add the companion chunk on the proper earlier than hashing and typically on the left, and if the index used to confirm the proof is totally different then the proof is not going to match. Thus, if I ask for a proof of piece 422, and you as a substitute present even a legitimate proof of piece 587, I’ll discover that one thing is incorrect. Additionally, there is no such thing as a approach to offer a proof with out possession of the whole related part of the Merkle tree; for those who attempt to go off pretend information, in some unspecified time in the future the hashes will mismatch and the closing root shall be totally different.
Now, let’s go over the protocol. I assemble a Merkle tree out of the file as described above, and add this to some get together. Then, each 12 hours, I decide a random quantity in [0, 2^k-1] and submit that quantity as a problem. If the storer replies again with a Merkle tree proof, then I confirm the proof and whether it is appropriate ship 0.001 BTC (or ETH, or storjcoin, or no matter different token is used). If I obtain no proof or an invalid proof, then I don’t ship BTC. If the storer shops the whole file, they may succeed 100% of the time, in the event that they retailer 50% of the file they may succeed 50% of the time, and so forth. If we need to make it all-or-nothing, then we are able to merely require the storer to resolve ten consecutive proofs with a purpose to get a reward. The storer can nonetheless get away with storing 99%, however then we reap the benefits of the identical redundant coding technique that I discussed above and will describe under to make 90% of the file adequate in any case.
One concern that you might have at this level is privateness – for those who use a cryptographic protocol to let any node receives a commission for storing your file, would that not imply that your information are unfold round the web in order that anybody can probably entry them? Thankfully the reply to that is easy: encrypt the file earlier than sending it out. From this level on, we’ll assume that each one information is encrypted, and ignore privateness as a result of the presence of encryption resolves that problem virtually fully (the “almost” being that the dimension of the file, and the occasions at which you entry the file, are nonetheless public).
Trying to Decentralize
So now we’ve a protocol for paying individuals to retailer your information; the algorithm may even be made trust-free by placing it into an Ethereum contract, utilizing
block.prevhash as a supply of random information to generate the challenges. Now let’s go to the subsequent step: determining methods to decentralize the storage and add redundancy. The best approach to decentralize is straightforward replication: as a substitute of 1 node storing one copy of the file, we are able to have 5 nodes storing one copy every. Nonetheless, if we merely observe the naive protocol above, we’ve an issue: one node can fake to be 5 nodes and acquire a 5x return. A fast repair to that is to encrypt the file 5 occasions, utilizing 5 totally different keys; this makes the 5 similar copies indistinguishable from 5 totally different information, so a storer won’t be able to note that the 5 information are the identical and retailer them as soon as however declare a 5x reward.
However even right here we’ve two issues. First, there is no such thing as a approach to confirm that the 5 copies of the file are saved by 5 separate customers. If you wish to have your file backed up by a decentralized cloud, you’re paying for the service of decentralization; it makes the protocol have a lot much less utility if all 5 customers are literally storing every thing by Google and Amazon. That is truly a tough drawback; though encrypting the file 5 occasions and pretending that you’re storing 5 totally different information will forestall a single actor from accumulating a 5x reward with 1x storage, it can not forestall an actor from accumulating a 5x reward with 5x storage, and economies of scale imply even that state of affairs shall be fascinating from the viewpoint of some storers. Second, there’s the problem that you’re taking a big overhead, and particularly taking the false-redundancy problem into consideration you’re actually not getting that a lot redundancy from it – for instance, if a single node has a 50% likelihood of being offline (fairly cheap if we’re speaking a few community of information being saved in the spare area on individuals’s onerous drives), then you could have a 3.125% likelihood at any level that the file shall be inaccessible outright.
There may be one resolution to the first drawback, though it’s imperfect and it isn’t clear if the advantages are price it. The concept is to make use of a mix of proof of stake and a protocol known as “proof of custody” – proof of simultaneous possession of a file and a non-public key. If you wish to retailer your file, the concept is to randomly choose some variety of stakeholders in some foreign money, weighting the chance of choice by the variety of cash that they’ve. Implementing this in an Ethereum contract would possibly contain having members deposit ether in the contract (bear in mind, deposits are trust-free right here if the contract supplies a approach to withdraw) and then giving every account a chance proportional to its deposit. These stakeholders will then obtain the alternative to retailer the file. Then, as a substitute of the easy Merkle tree examine described in the earlier part, the proof of custody protocol is used.
The proof of custody protocol has the profit that it’s non-outsourceable – there is no such thing as a approach to put the file onto a server with out giving the server entry to your personal key at the identical time. Because of this, at the least in principle, customers shall be a lot much less inclined to retailer giant portions of information on centralized “cloud” computing programs. After all, the protocol accomplishes this at the value of a lot increased verification overhead, in order that leaves open the query: do we wish the verification overhead of proof of custody, or the storage overhead of getting additional redundant copies simply in case?
M of N
No matter whether or not proof of custody is a good suggestion, the subsequent step is to see if we are able to perform a little higher with redundancy than the naive replication paradigm. First, let’s analyze how good the naive replication paradigm is. Suppose that every node is on the market 50% of the time, and you’re prepared to take 4x overhead. In these instances, the likelihood of failure is
0.5 ^ 4 = 0.0625 – a fairly excessive worth in comparison with the “four nines” (ie. 99.99% uptime) provided by centralized companies (some centralized companies provide 5 – 6 nines, however purely due to Talebian black swan considerations any guarantees over three nines can usually be thought-about bunk; as a result of decentralized networks don’t rely on the existence or actions of any particular firm or hopefully any particular software program package deal, nonetheless, decentralized programs arguably truly can promise one thing like 4 nines legitimately). If we assume that the majority of the community shall be quasi-professional miners, then we are able to scale back the unavailability share to one thing like 10%, through which case we truly do get 4 nines, but it surely’s higher to imagine the extra pessimistic case.
What we thus want is a few type of M-of-N protocol, very like multisig for Bitcoin. So let’s describe our dream protocol first, and fear about whether or not it is possible later. Suppose that we’ve a file of 1 GB, and we need to “multisig” it right into a 20-of-60 setup. We cut up the file up into 60 chunks, every 50 MB every (ie. 3 GB whole), such that any 20 of these chunks suffice to reconstruct the unique. That is information-theoretically optimum; you’ll be able to’t reconstruct a gigabyte out of lower than a gigabyte, however reconstructing a gigabyte out of a gigabyte is totally attainable. If we’ve this sort of protocol, we are able to use it to separate every file up into 60 items, encrypt the 60 chunks individually to make them appear to be unbiased information, and use an incentivized file storage protocol on each individually.
Now, right here comes the enjoyable half: such a protocol truly exists. On this subsequent a part of the article, we’re going to describe a bit of math that’s alternately known as both “secret sharing” or “erasure coding” relying on its software; the algorithm used for each these names is mainly the identical with the exception of 1 implementation element. To start out off, we are going to recall a easy perception: two factors make a line.
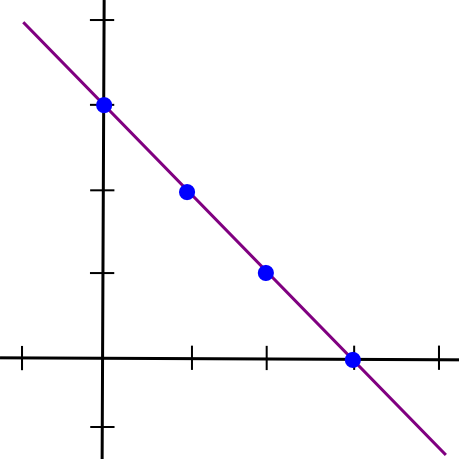
x = 1and the second half as the y coordinate of the line at
x = 2, draw the line, and take factors at
x = 3,
x = 4, and so forth. Any two items can then be used to reconstruct the line, and from there derive the y coordinates at
x = 1and
x = 2 to get the file again.
Mathematically, there are two methods of doing this. The primary is a comparatively easy method involving a system of linear equations. Suppose that we file we need to cut up up is the quantity “1321”. The left half is 13, the proper half is 21, so the line joins (1, 13) and (2, 21). If we need to decide the slope and y-intercept of the line, we are able to simply remedy the system of linear equations:
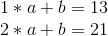
Subtract the first equation from the second, and you get:
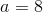
After which plug that into the first equation, and get:
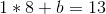
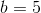
So we’ve our equation, y = 8 * x + 5. We will now generate new factors: (3, 29), (4, 37), and so forth. And from any two of these factors we are able to get well the unique equation.
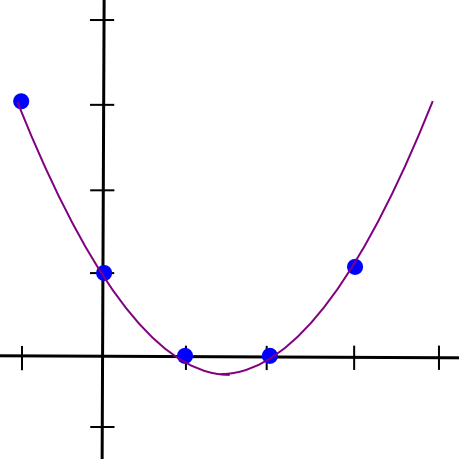
Now, let’s go one step additional, and generalize this into m-of-n. Because it seems, it is extra sophisticated however not too troublesome. We all know that two factors make a line. We additionally know that three factors make a parabola:
x = 1, 2, 3, and take additional factors on the parabola as extra items. If we wish 4-of-n, we use a cubic polynomial as a substitute. Let’s undergo that latter case; we nonetheless hold our unique file, “1321”, however we’ll cut up it up utilizing 4-of-7 as a substitute. Our 4 factors are
(1, 1),
(2, 3),
(3, 2),
(4, 1). So we’ve:
Eek! Properly, let’s, uh, begin subtracting. We’ll subtract equation 1 from equation 2, 2 from 3, and 3 from 4, to scale back 4 equations to a few, and then repeat that course of once more and once more.
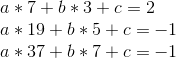
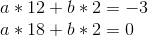
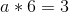
So a = 1/2. Now, we unravel the onion, and get:
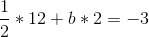
So b = -9/2, and then:
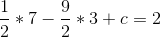
So c = 12, and then:
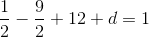
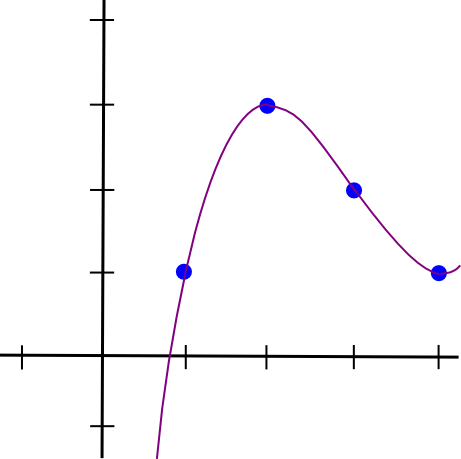
So a = 0.5, b = -4.5, c = 12, d = -7. This is the pretty polynomial visualized:
I created a Python utility that can assist you do that (this utility additionally does different extra superior stuff, however we’ll get into that later); you’ll be able to obtain it here. Should you needed to resolve the equations shortly, you’d simply kind in:
> import share > share.sys_solve([[1.0, 1.0, 1.0, 1.0, -1.0], [8.0, 4.0, 2.0, 1.0, -3.0], [27.0, 9.0, 3.0, 1.0, -2.0], [64.0, 16.0, 4.0, 1.0, -1.0]]) [0.5, -4.5, 12.0, -7.0]
Observe that placing the values in as floating level is important; for those who use integers Python’s integer division will screw issues up.
Now, we’ll cowl the simpler approach to do it, Lagrange interpolation. The concept right here could be very intelligent: we provide you with a cubic polynomial whose worth is 1 at x = 1 and 0 at x = 2, 3, 4, and do the identical for each different x coordinate. Then, we multiply and add the polynomials collectively; for instance, to match (1, 3, 2, 1) we merely take 1x the polynomial that passes by (1, 0, 0, 0), 3x the polynomial by (0, 1, 0, 0), 2x the polynomial by (0, 0, 1, 0) and 1x the polynomial by (0, 0, 0, 1) and then add these polynomials collectively to get the polynomal by (1, 3, 2, 1) (be aware that I stated the polynomial passing by (1, 3, 2, 1); the trick works as a result of 4 factors outline a cubic polynomial uniquely). This won’t appear simpler, as a result of the solely approach we’ve of becoming polynomials to factors to far is the cumbersome process above, however thankfully, we even have an express development for it:
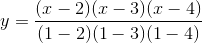
At x = 1, discover that the high and backside are similar, so the worth is 1. At x = 2, 3, 4, nonetheless, one among the phrases on the high is zero, so the worth is zero. Multiplying up the polynomials takes quadratic time (ie. ~16 steps for 4 equations), whereas our earlier process took cubic time (ie. ~64 steps for 4 equations), so it is a substantial enchancment particularly as soon as we begin speaking about bigger splits like 20-of-60. The python utility helps this algorithm too:
> import share > share.lagrange_interp([1.0, 3.0, 2.0, 1.0], [1.0, 2.0, 3.0, 4.0]) [-7.0, 12.000000000000002, -4.5, 0.4999999999999999]
The primary argument is the y coordinates, the second is the x coordinates. Observe the reverse order right here; the code in the python module places the lower-order coefficients of the polynomial first. And at last, let’s get our extra shares:
> share.eval_poly_at([-7.0, 12.0, -4.5, 0.5], 5) 3.0 > share.eval_poly_at([-7.0, 12.0, -4.5, 0.5], 6) 11.0 > share.eval_poly_at([-7.0, 12.0, -4.5, 0.5], 7) 28.0
So right here instantly we are able to see two issues. First, it appears like computerized floating level numbers aren’t infinitely exact in any case; the 12 changed into 12.000000000000002. Second, the chunks begin getting giant as we transfer additional out; at x = 10, it goes as much as 163. That is considerably breaking the promise that the quantity of knowledge you have to get well the file is the identical dimension as the unique file; if we lose x = 1, 2, 3, 4 then you definitely want 8 digits to get the unique values again and not 4. These are each critical points, and ones that we are going to resolve with some extra mathematical cleverness later, however we’ll go away them apart for now.
Even with these points remaining, we’ve mainly achieved victory, so let’s calculate our spoils. If we use a 20-of-60 cut up, and every node is on-line 50% of the time, then we are able to use combinatorics – particularly, the binomial distribution formula – to compute the chance that our information is okay. First, to set issues up:
> def fac(n): return 1 if n==0 else n * fac(n-1) > def select(n,okay): return fac(n) / fac(okay) / fac(n-k) > def prob(n,okay,p): return select(n,okay) * p ** okay * (1-p) ** (n-k)
The final formulation computes the chance that precisely okay servers out of n shall be on-line if every particular person server has a chance p of being on-line. Now, we’ll do:
> sum([prob(60, k, 0.5) for k in range(0, 20)]) 0.0031088013296633353
99.7% uptime with solely 3x redundancy – a very good step up from the 87.5% uptime that 3x redundancy would have given us had easy replication been the solely device in our toolkit. If we crank the redundancy as much as 4x, then we get six nines, and we are able to cease there as a result of the chance both Ethereum or the whole web will crash outright is larger than 0.0001% anyway (in reality, you are more likely to die tomorrow). Oh, and if we assume every machine has 90% uptime (ie. hobbyist “farmers”), then with a 1.5x-redundant 20-of-30 protocol we get a fully overkill twelve nines. Popularity programs can be utilized to maintain observe of how usually every node is on-line.
Coping with Errors
We’ll spend the remainder of this text discussing three extensions to this scheme. The primary is a priority that you might have disregarded studying the above description, however one which is nonetheless essential: what occurs if some node tries to actively cheat? The algorithm above can get well the unique information of a 20-of-60 cut up from any 20 items, however what if one among the information suppliers is evil and tries to offer pretend information to screw with the algorithm. The assault vector is a fairly compelling one:
> share.lagrange_interp([1.0, 3.0, 2.0, 5.0], [1.0, 2.0, 3.0, 4.0]) [-11.0, 19.333333333333336, -8.5, 1.1666666666666665]
Taking the 4 factors of the above polynomial, however altering the final worth to five, provides a very totally different consequence. There are two methods of coping with this drawback. One is the apparent approach, and the different is the mathematically intelligent approach. The plain approach is clear: when splitting a file, hold the hash of every chunk, and evaluate the chunk towards the hash when receiving it. Chunks that don’t match their hashes are to be discarded.
The intelligent approach is considerably extra intelligent; it includes some spooky not-quite-moon-math known as the Berlekamp-Welch algorithm. The concept is that as a substitute of becoming only one polynomial, P, we think about into existence two polynomials, Q and E, such that Q(x) = P(x) * E(x), and attempt to remedy for each Q and E at the identical time. Then, we compute P = Q / E. The concept is that if the equation holds true, then for all x both P(x) = Q(x) / E(x) or E(x) = 0; therefore, other than computing the unique polynomial we magically isolate what the errors are. I will not go into an instance right here; the Wikipedia article has a wonderfully respectable one, and you’ll be able to attempt it your self with:
> map(lambda x: share.eval_poly_at([-7.0, 12.0, -4.5, 0.5], x), [1, 2, 3, 4, 5, 6]) [1.0, 3.0, 2.0, 1.0, 3.0, 11.0] > share.berlekamp_welch_attempt([1.0, 3.0, 18018.0, 1.0, 3.0, 11.0], [1, 2, 3, 4, 5, 6], 3) [-7.0, 12.0, -4.5, 0.5] > share.berlekamp_welch_attempt([1.0, 3.0, 2.0, 1.0, 3.0, 0.0], [1, 2, 3, 4, 5, 6], 3) [-7.0, 12.0, -4.5, 0.5]
Now, as I discussed, this mathematical trickery shouldn’t be actually all that wanted for file storage; the easier method of storing hashes and discarding any piece that doesn’t match the recorded hash works simply effective. However it’s by the way fairly helpful for one other software: self-healing Bitcoin addresses. Bitcoin has a base58check encoding algorithm, which can be utilized to detect when a Bitcoin deal with has been mistyped and returns an error so you don’t by chance ship 1000’s of {dollars} into the abyss. Nonetheless, utilizing what we all know, we are able to truly do higher and make an algorithm which not solely detects mistypes but additionally truly corrects the errors on the fly. We do not use any type of intelligent deal with encoding for Ethereum as a result of we favor to encourage use of title registry-based alternate options, but when an deal with encoding scheme was demanded one thing like this could possibly be used.
Finite Fields
Now, we get again to the second drawback: as soon as our x coordinates get slightly increased, the y coordinates begin capturing off in a short time towards infinity. To unravel this, what we’re going to do is nothing in need of fully redefining the guidelines of arithmetic as we all know them. Particularly, let’s redefine our arithmetic operations as:
a + b := (a + b) % 11 a - b := (a - b) % 11 a * b := (a * b) % 11 a / b := (a * b ** 9) % 11
That “percent” signal there’s “modulo”, ie. “take the remainder of dividing that vaue by 11”, so we’ve
7 + 5 = 1,
6 * 6 = 3(and its corollary
3 / 6 = 6), and so forth. We are actually solely allowed to cope with the numbers 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. The shocking factor is that, whilst we do that, all of the guidelines about conventional arithmetic nonetheless maintain with our new arithmetic;
(a * b) * c = a * (b * c),
(a + b) * c = (a * c) + (b * c),
a / b * b = aif
b != 0,
(a^2 - b^2) = (a - b)*(a + b), and so forth. Thus, we are able to merely take the algebra behind our polynomial encoding that we used above, and transplant it over into the new system. Despite the fact that the instinct of a polynomial curve is totally borked – we’re now coping with summary mathematical objects and not something resembling precise factors on a aircraft – as a result of our new algebra is self-consistent, the formulation nonetheless work, and that is what counts.
> e = share.mkModuloClass(11) > P = share.lagrange_interp(map(e, [1, 3, 2, 1]), map(e, [1, 2, 3, 4])) > P [4, 1, 1, 6] > map(lambda x: share.eval_poly_at(map(e, P), e(x)), vary(1, 9)) [1, 3, 2, 1, 3, 0, 6, 2] > share.berlekamp_welch_attempt(map(e, [1, 9, 9, 1, 3, 0, 6, 2]), map(e, [1, 2, 3, 4, 5, 6, 7, 8]), 3) [4, 1, 1, 6]
The “
map(e, [v1, v2, v3])” is used to transform strange integers into components on this new subject; the software program library contains an implementation of our loopy modulo 11 numbers that interfaces with arithmetic operators seamlessly so we are able to merely swap them in (eg.
print e(6) * e(6)returns
3). You possibly can see that every thing nonetheless works – besides that now, as a result of our new definitions of addition, subtraction, multiplication and division at all times return integers in
[0 ... 10] we by no means want to fret about both floating level imprecision or the numbers increasing as the x coordinate will get too excessive.
Now, in actuality these comparatively easy modulo finite fields aren’t what are often utilized in error-correcting codes; the usually most popular development is one thing known as a Galois field (technically, any subject with a finite variety of components is a Galois subject, however typically the time period is used particularly to discuss with polynomial-based fields as we are going to describe right here). The concept is that the components in the subject are actually polynomials, the place the coefficients are themselves values in the subject of integers modulo 2 (ie. a + b := (a + b) % 2, and so forth). Including and subtracting work as usually, however multiplying is itself modulo a polynomial, particularly x^8 + x^4 + x^3 + x + 1. This fairly sophisticated multilayered development lets us have a subject with precisely 256 components, so we are able to conveniently retailer each aspect in a single byte and each byte as one aspect. If we need to work on chunks of many bytes at a time, we merely apply the scheme in parallel (ie. if every chunk is 1024 bytes, decide 10 polynomials, one for every byte, prolong them individually, and mix the values at every x coordinate to get the chunk there).
However it isn’t essential to know the actual workings of this; the salient level is that we are able to redefine +, –, * and / in such a approach that they’re nonetheless totally self-consistent however at all times take and output bytes.
Going Multidimensional: The Self-Therapeutic Dice
Now, we’re utilizing finite fields, and we are able to cope with errors, however one problem nonetheless stays: what occurs when nodes do go down? At any cut-off date, you’ll be able to rely on 50% of the nodes storing your file staying on-line, however what you can’t rely on is the identical nodes staying on-line endlessly – finally, just a few nodes are going to drop out, then just a few extra, then just a few extra, till finally there aren’t sufficient of the unique nodes left on-line. How can we combat this gradual attrition? One technique is that you could possibly merely watch the contracts which might be rewarding every particular person file storage occasion, seeing when some cease paying out rewards, and then re-upload the file. Nonetheless, there’s a drawback: with a purpose to re-upload the file, you have to reconstruct the file in its entirety, a probably troublesome job for the multi-gigabyte films that are actually wanted to fulfill individuals’s seemingly insatiable needs for multi-thousand pixel decision. Moreover, ideally we want the community to have the ability to heal itself with out requiring lively involvement from a centralized supply, even the proprietor of the information.
Thankfully, such an algorithm exists, and all we have to accomplish it’s a intelligent extension of the error correcting codes that we described above. The elemental concept that we are able to depend on is the undeniable fact that polynomial error correcting codes are “linear”, a mathematical time period which mainly implies that it interoperates properly with multiplication and addition. For instance, contemplate:
> share.lagrange_interp([1.0, 3.0, 2.0, 1.0], [1.0, 2.0, 3.0, 4.0]) [-7.0, 12.000000000000002, -4.5, 0.4999999999999999] > share.lagrange_interp([10.0, 5.0, 5.0, 10.0], [1.0, 2.0, 3.0, 4.0]) [20.0, -12.5, 2.5, 0.0] > share.lagrange_interp([11.0, 8.0, 7.0, 11.0], [1.0, 2.0, 3.0, 4.0]) [13.0, -0.5, -2.0, 0.5000000000000002] > share.lagrange_interp([22.0, 16.0, 14.0, 22.0], [1.0, 2.0, 3.0, 4.0]) [26.0, -1.0, -4.0, 1.0000000000000004]
See how the enter to the third interpolation is the sum of the inputs to the first two, and the output finally ends up being the sum of the first two outputs, and then after we double the enter it additionally doubles the output. So what’s the advantage of this? Properly, here is the intelligent trick. Erasure cording is itself a linear formulation; it depends solely on multiplication and addition. Therefore, we’re going to apply erasure coding to itself. So how are we going to do that? Right here is one attainable technique.
First, we take our 4-digit “file” and put it right into a 2×2 grid.
Then, we use the identical polynomial interpolation and extension course of as above to increase the file alongside each the x and y axes:
1 3 5 7 2 1 0 10 3 10 4 8
After which we apply the course of once more to get the remaining 4 squares:
1 3 5 7 2 1 0 10 3 10 6 2 4 8 1 5
Observe that it would not matter if we get the final 4 squares by increasing horizontally and vertically; as a result of secret sharing is linear it’s commutative with itself, so that you get the very same reply both approach. Now, suppose we lose a quantity in the center, say, 6. Properly, we are able to do a restore vertically:
> share.restore([5, 0, None, 1], e) [5, 0, 6, 1]
Or horizontally:
> share.restore([3, 10, None, 2], e) [3, 10, 6, 2]
And tada, we get 6 in each instances. That is the shocking factor: the polynomials work equally nicely on each the x or the y axis. Therefore, if we take these 16 items from the grid, and cut up them up amongst 16 nodes, and one among the nodes disappears, then nodes alongside both axis can come collectively and reconstruct the information that was held by that individual node and begin claiming the reward for storing that information. Ideally, we are able to even prolong this course of past 2 dimensions, producing a third-dimensional dice, a four-dimensional hypercube or extra – the acquire of utilizing extra dimensions is ease of reconstruction, and the value is a decrease diploma of redundancy. Thus, what we’ve is an information-theoretic equal of one thing that sounds prefer it got here straight out of science-fiction: a extremely redundant, interlinking, modular self-healing dice, that may shortly domestically detect and repair its personal errors even when giant sections of the dice have been to be broken, co-opted or destroyed.

“The cube can still function even if up to 78% of it were to be destroyed…”
So, let’s put all of it collectively. You could have a ten GB file, and you need to cut up it up throughout the community. First, you encrypt the file, and then you definitely cut up the file into, to illustrate, 125 chunks. You prepare these chunks right into a third-dimensional 5x5x5 dice, work out the polynomial alongside every axis, and “extend” each in order that at the finish you could have a 7x7x7 dice. You then look for 343 nodes prepared to retailer each bit of knowledge, and inform every node solely the identification of the different nodes which might be alongside the identical axis (we need to make an effort to keep away from a single node gathering collectively a complete line, sq. or dice and storing it and calculating any redundant chunks as wanted in real-time, getting the reward for storing all the chunks of the file with out truly offering any redundancy.
So as to truly retrieve the file, you’d ship out a request for all of the chunks, then see which of the items coming in have the highest bandwidth. It’s possible you’ll use the pay-per-chunk protocol to pay for the sending of the information; extortion shouldn’t be a problem as a result of you could have such excessive redundancy so nobody has the monopoly energy to disclaim you the file. As quickly as the minimal variety of items arrive, you’d do the math to decrypt the items and reconstitute the file domestically. Maybe, if the encoding is per-byte, it’s possible you’ll even be capable to apply this to a Youtube-like streaming implementation, reconstituting one byte at a time.
In some sense, there’s an unavoidable tradeoff between self-healing and vulnerability to this sort of pretend redundancy: if components of the community can come collectively and get well a lacking piece to offer redundancy, then a malicious giant actor in the community can get well a lacking piece on the fly to offer and cost for pretend redundancy. Maybe some scheme involving including one other layer of encryption on each bit, hiding the encryption keys and the addresses of the storers of the particular person items behind one more erasure code, and incentivizing the revelation course of solely at some explicit occasions would possibly kind an optimum steadiness.
Secret Sharing
At the starting of the article, I discussed one other title for the idea of erasure coding, “secret sharing”. From the title, it is easy to see how the two are associated: if in case you have an algorithm for splitting information up amongst 9 nodes such that 5 of 9 nodes are wanted to get well it however 4 of 9 cannot, then one other apparent use case is to make use of the identical algorithm for storing personal keys – cut up up your Bitcoin pockets backup into 9 components, give one to your mom, one to your boss, one to your lawyer, put three into just a few security deposit containers, and so forth, and for those who neglect your password then you can ask every of them individually and chances are high at the least 5 provides you with your items again, however the people themselves are sufficiently far aside from one another that they are unlikely to collude with one another. It is a very authentic factor to do, however there’s one implementation element concerned in doing it proper.
The problem is that this: although 4 of 9 cannot get well the unique key, 4 of 9 can nonetheless come collectively and have various details about it – particularly, 4 linear equations over 5 unknowns. This reduces the dimensionality of the alternative area by an element of 5, so as a substitute of two256 personal keys to go looking by they now have solely 251. In case your secret’s 180 bits, that goes right down to 236 – trivial work for a fairly highly effective pc. The way in which we repair that is by erasure-coding not simply the personal key, however fairly the personal key plus 4x as many bytes of random gook. Extra exactly, let the personal key be the zero-degree coefficient of the polynomial, decide 4 random values for the subsequent 4 coefficients, and take values from that. This makes each bit 5 occasions longer, however with the profit that even 4 of 9 now have the whole alternative area of two180 or 2256 to go looking by.
Conclusion
So there we go, that is an introduction to the energy of erasure coding – arguably the single most underhyped set of algorithms (besides maybe SCIP) in pc science or cryptography. The concepts right here primarily are to file storage what multisig is to good contracts, permitting you to get the completely most attainable quantity of safety and redundancy out of no matter ratio of storage overhead you’re prepared to just accept. It is an method to file storage availability that strictly supersedes the potentialities provided by easy splitting and replication (certainly, replication is definitely precisely what you get for those who attempt to apply the algorithm with a 1-of-n technique), and can be utilized to encapsulate and individually deal with the drawback of redundancy in the identical approach that encryption encapsulates and individually handles the drawback of privateness.
Decentralized file storage continues to be removed from a solved drawback; though a lot of the core expertise, together with erasure coding in Tahoe-LAFS, has already been carried out, there are actually many minor and not-so-minor implementation particulars that also should be solved for such a setup to really work. An efficient popularity system shall be required for measuring quality-of-service (eg. a node up 99% of the time is price at the least 3x greater than a node up 50% of the time). In some methods, incentivized file storage even depends upon efficient blockchain scalability; having to implicitly pay for the charges of 343 transactions going to verification contracts each hour shouldn’t be going to work till transaction charges grow to be far decrease than they’re right now, and till then some extra coarse-grained compromises are going to be required. However then once more, just about each drawback in the cryptocurrency area nonetheless has a really lengthy approach to go.




